Understanding and selecting databases in NoSQL DBMS [Part1] - Types of NoSQL DBMS
![Understanding and selecting databases in NoSQL DBMS [Part1] - Types of NoSQL DBMS](/content/images/size/w960/2022/04/Understanding-and-selecting-databases-in-NoSQL-DBMS_Mesa-de-trabajo-1.png)
Hello brothers! In today's technology era, there are many ways to solve a problem. Database (exactly DBMS - database management system) too, there are more and more new engines to meet the needs of users. DBMS can be divided into two types: RDBMS (relational database management system) and NoSQL DBMS.
NoSQL was born late but rose up quite quickly because there are properties and features that RDBMS does not support. Is there anyone here who comes into contact with NoSQL DBMS every day but is a bit vague, and has no general and specific view of it? Anyone working on systems using MongoDB, or Redis, but don't really understand them? Is anyone building up a project but wondering what kind of database to choose? To solve those problems, I will talk about NoSQL types, dive into their properties and deduce their use cases.
Types of NoSQL DBMS:
- Key-value store
- Document store
- Wide column store
- Graph store
1. Key-value store
Define:
The simplest data model. Once I know the key, this pattern is the fastest way to get the value. This model has no query language, but it still provides a way to store, retrieve, and update data using simple get, put, and delete commands.
Example:
DBMS: Redis, Amazon DynamoDB, FoundationDB.
Twitter uses Redis to deliver the Twitter timeline(Link).
Pinterest uses Redis to store lists of users, followers, un-followers, and more(Link).
Redis is frequently used as a Caching database to speed up the application.
Use cases:
Share data between applications as distributed cache or to store user session data, user preferences and profiles, shopping carts, and even Real-time bidding.
Explain:
In this day and age, applications built up often go hand in hand with authentication/authorization, even if there are systems where every application uses a single identity server for authentication, handling authentication/authorization is very important. important. One of those ways is the session store, if you know the session, please pass the fake story I'm about to tell:
Our system only implements basic authentication, or only uses tokens, then our server-side is quite free, without having to store any more user login information. Then one day there was a call from 1 VIP customer:
VIP customer: - Honey, someone is using my account, get out for me.
We: Hmm, can we... How can I let him log out, while our system lets the client store all login information, not keep this information on the server? So I can only wait until the login session has expired.
VIP customer: - What's wrong, can you come out yet?
We: - Yes, let me implement it more. Half a year later bro.:D
VIP customer: - Aaaaa
See, the customer is king, we have to pamper even the most difficult customers. But no matter what, we have to protect our users! Back to the problem, if you don't store anything on your server, how can you manage it tightly? So we will store the session for strong management of authentication/authorization. Also, imagine a user is using multiple apps of one system, and then from one of those apps log out from account 1 and log in to account 2, the other apps are still using the token of account 1, do not log out nor switch to account 2, at this time the apps are not synchronized and unified. The above issues have shown how important it is to store the user session or the user's information (depending on how it is handled, it can be a token) on the server-side.
End of session. Next, I know that storing user sessions is important, but why do we use this Key-value store?
- Simply because it's simple. No need for complicated queries but just need to store the session, when needed, get, update the value just need to know the key.
- In the next case, this model is used for shopping cart and Real-time bidding, while in the past, we still think we should choose RDBMS instead of using the NoSQL key for the cases related to money.
Nope. RDBMS is very strong in terms of consistency, but when is implemented on a distributed system, it is still eventually consistent. Meaning that in Asia, when you check the request, you will see a package of instant noodles with tomatoes in the basket, thinking that you will eat noodles like the below, but when you check in America, you only see tomatoes (so you will probably starve to death)

So I affirm that NoSQL still has a position when it comes to handling systems in real-time, it supports scale-out very well, so there is nothing we have to be afraid of. Are you asking me what approach this key-value store use? Noted that bidding is important from moment to moment, if we don't handle it well, a low-priced bid will win a high-priced bid, or the bidding results will be different on servers around the world.

Because if this model is applied, near real-time, the propagation latency of the databases is very low, that is, the time when the databases are not consistent is very low. What is the secret of this model? It is in its simplicity.
When we hold a tinder (complex value) in our hand, we will check it, handle it, then pass it on to someone else, then that person will suspect, have to check whether the tinder has a needle or not. Time out! Now that we only use extremely simple values, do the systems have to process and check a lot? No! Nice choice!
More, some database servers increase the speed even more by using SSD drives or flash storage, what's wrong with this style :D
2. Document store
Define:
The data model for storing document objects in a semi-structured and metadata, schema-free style. This model is also a key value, but the value here is an entire object that is more complex than the key-value type earlier. Datasets that follow this model often use the JSON format to represent objects.
But JSON type support is not as rich as BSON, so please pay attention to this issue. Currently, I know that MongoDB and LiteDB support the BSON format.
Example:
DBMS: MongoDB, CouchDB, Elasticsearch, Solr.
SEGA uses MongoDB to handle tens of millions of accounts in the game.
Chicago uses MongoDB to create the WindyGrid app, which helps manage the city in a smarter, safer way(Link)
EO Media Group: Increase website engagement with a powerful Search feature (Link)
Use cases:
Handling objects without complex data, to quickly search or filter by several object properties.
Explain:
This model is too common in NoSQL DBMS. Because it's document-oriented, each document does not depend on anything, and is flexible - this document can have these properties that another document may not have, is optional, and has no constraints. It's very easy to represent objects and when inserting updates, it doesn't fail because there are no constraints.
This model is also familiar to you, but please note that although this model is quite similar to the row-based RDBMS, there is a huge difference. In RDBMS there are less data duplication thanks to foreign key but also because of that there is a problem. For example, updating the data of a row in this table, but the database must lock that row, lock the page, or even lock the table (depending on the mechanism of the current database and the size and impact of the change) and lock the data that will be affected. Then, changing schemas is also more difficult than NoSQL, while in a context distributed system, this change will lead to a bunch of database brothers changing (if they also use RDBMS).
However, everything has its advantages and disadvantages, schema-less, flexible but must be accompanied by good handling. If you are too generous, you have to be careful, or you will have problems!
3. Wide column store (Big table)
Define:
The wide column store, also known as BigTable, or extensible record store, is a data model for storing data with the ability to contain many columns, and the column here is a dynamic column. Column names can change, so we can think of this model as a two-way key-value store. A pair whose key is the object id and column name, and the value is the object's information.
Example:
DBMS: Cassandra, HBase, Microsoft Azure Cosmos DB.
Spotify uses Cassandra to store user profiles and metadata about artists, songs, and more for better personalization (Link).
Facebook: "Recent friends" feature and search indexing (Link).
Use cases:
Works well in distributed systems. When we have so much data that we think we have to spread it across many computers, we should consider a database of the type Wide column store.
Explain:
This model also has the same things as Document oriented, is also schema-free, and can still search based on fields, but the implementation is very different, you can review the definition to understand.
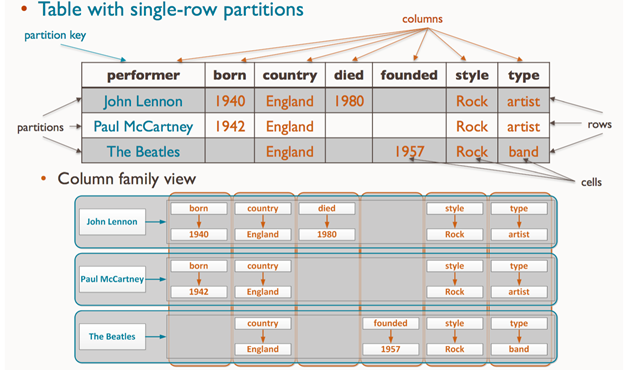
In addition to distinguishing it from Document oriented, we also need to avoid confusion with column-oriented storage of RDBMS. It's a form of improving the performance of RDBMS, focusing on columns, and saving data to columns instead of rows, their query is still the same but access the right part of the data you want instead of scanning the whole row and getting the unwanted data and then filtering out the column I want, very useful for analysis.
4. Graph store
Define
The model is designed for relational data that is well represented as a graph and whose elements are linked together, with an unknown number of relationships between them.
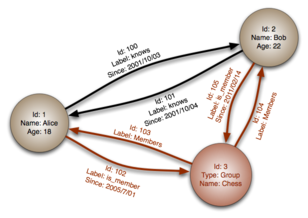
In the image above, the circle is Node, and the arrows are Edge, the information in the node is Properties.
The node represents entities like a person, account... They are roughly equivalent to records, relations, or rows in the relational database or documents in the Document store.
Edges: also known as relationships are lines that connect nodes, representing relationships between them. Edges can be directed or undirected. In an undirected graph, an edge from one point to another has the same meaning. In a directed graph, edges connecting two different points have different meanings depending on their orientation. Edges are a key concept in graph databases, representing abstractions that are not directly implemented in the relational or document storage model. You can review your knowledge of undirected graphs if you want to deeply understand the model.
Properties: is information related to nodes.
The Graph model is divided into two sub-models: RDF and Labeled Property Graph Models.
Graph DBMS has many types such as Social graph, Intent graph, Consumption graph, Interest graph, Mobile graph.
Example:
DBMS: Neo4j, Titan.
Are you familiar with Medium? Medium uses Neo4j to build the social graph. Another is that Walmart uses Neo4j to recommend to customers relevant, personalized product recommendations and promotions.
Use cases:
Systems that require data with a large number of flexible relationships, require an extensible structure to add new data and require querying of relationships in real-time.
Explain:
Labeled Property Graph Models: This model will be suitable for systems that rarely exchange or publish data but only focus on storage, efficient storage will allow for fast queries. Nodes have unique IDs and a set of key-value pairs or properties that are specific to them. And when we know the node's ID, we can definitely identify that node and its associated values - what we need. Example of this model:
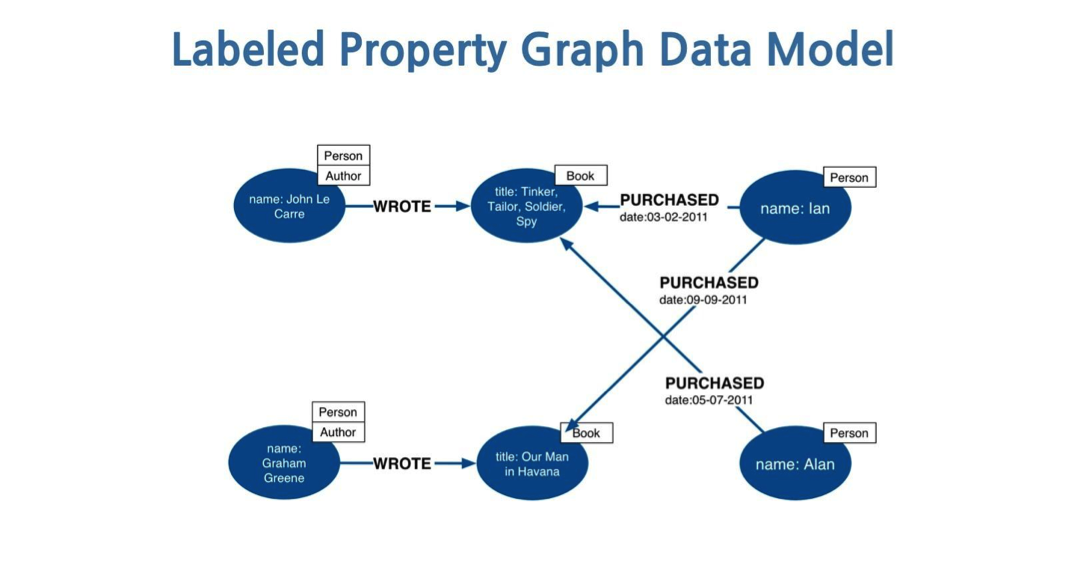
Next is RDF (also known as semantic graph database): this model is more related to data exchange. The core of RDF is the triple concept, consisting of three elements representing two vertices connected by an edge. These three elements will have meaning: subject-predicate-object. Subject and object are nodes. The predicate is an edge, representing the relationship between them. The node here can be a literal value (in text) or a URI, unlike the previous model, both nodes and edges have no internal structure (containing a set of key-value pairs).
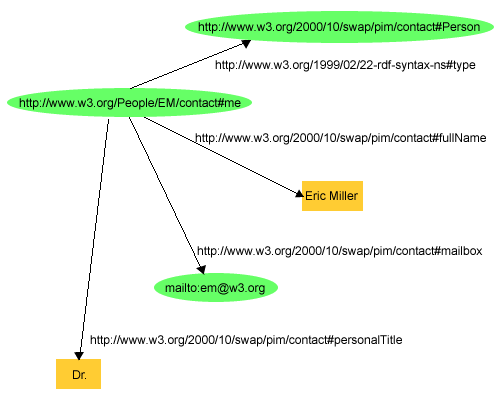
It's a bit long, but you just need to look at the picture above, and "understood" is ok. It is showing a Me object which is a Person named Eric Miller, whose email is em@w3.org and whose title is Dr.
I have explained roughly the structure of this model, now let's move on to the properties.!
If you only know about Graph store, it will be easy to confuse with RDBMS. The Graph store is designed for relational data, but its structure is different from that of an RDBMS. RDBMS is very strict, has constraints, and 1 row can contain foreign keys that refer to other rows and tables, when querying to get our data we have to join all rows in the tables that are retrieving data, this is very computationally heavy. Because of this, NoSQL, although born late, is enthusiastically welcomed for its simplicity, flexibility, high performance, and highly scale-out. But, it lacks the ability to create relationships and connections between data. In the end, the Graph Store model has met that, but still retains good performance, better than RDBMS. Why is the Graph Store model able to query in real-time, faster than RDBMS? This is because the Graph Store stores the relationship on each record separately. It considers each node, each edge of equal importance, connected together into a simple model, allowing us to directly access the node we want without having to implement the join style of an RDBMS.
But, again, RDBMS will be good for storage in case the data has a relatively similar structure because the columns are already in the table definition, the additional rows contain only the value, not the information of the column, and the Graph will be more beneficial in case the structure between records is not fixed, the column name changes.
5. All types of NoSQL DBMBS are over?
Yes, I said there are only 4 types.
Just kidding, also, in addition to the 4 types above, there are a few types that can be mentioned as Search Engine. Search Engine is also quite popular now, is a specialized NoSQL DBMS for searching: complex query search, full-text search, ranking and grouping of search results, geospatial search (geographical location), even Even spatial search like GeoSeer, can mention famous DBMS implementing it like Elasticsearch, Splunk, Solr. Search Engine is not in 1 of the 4 basic types of NoSQL DBMS but it is independent!
Is it over?Yes
Just kidding again, there is one more "type", it's a bit special, it's not actually a type of DB, but I have to talk about it because there are times when selecting a DBMS, you can have a headache because wanting to have the benefits and features of the 2 3 models mentioned above at the same time, for example, you can choose one of the DBMS above.
Multi-Model:
Amazon DynamoDB uses 2 models, a Document store and a Key-value store.
OrientDB uses 3 models: Document store, Key-value store, and Graph store.
Microsoft Azure Cosmos DB: use all 4 models above.
I'll show you a picture to see if it matches the knowledge I said or not:
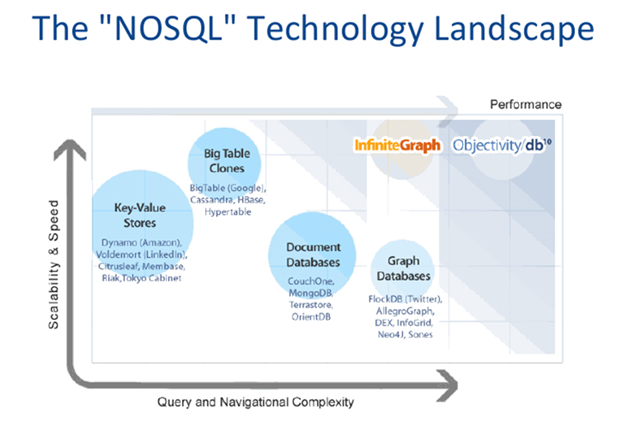
Conclusions
This is part 1 of the series Understanding and selecting databases in NoSQL DBMS. I only share the limited knowledge that I understand, but I still hope this reading will help you. If you have anything to add or suggest, please leave a comment.
See you in Part 2 - CAP theorem- Truth and application. Have a nice evening guys!